
在 SIOV 相关的技术栈中,反复出现 PASID、SVA、ENQCMD/S 等等名词。这里试图逐一对每个名词作个大致的了解,并在最后将这些概念串联起来。
PASID
PCIe PASID TLP Prefix
什么是 PASID?这个是 PCIe spec 引入的概念。
PASID TLP prefix 中包含 20 bit 位宽的 PASID value,用来作为使用者 process 的标识。它与 Requeseter ID (BDF) 结合起来,可以作为一个地址空间的标识。一个 Requester ID 内的 PASID 是唯一的;换句话说,不同的 Requester ID 下,可以使用数字相同的 PASID,两者的地址空间不冲突。携带 PASID prefix 后,每个进程可以在拥有独立的虚拟地址空间的情况下,共用同一个 EP 设备。
PASID 与 ATS、PRI 功能正交,没有依赖关系。
PASID TLP prefix 的格式:

IOASID in Linux
在 Linux 内核中,我们又会经常看到 IOASID 这个名词。IOASID 又是什么呢?
IOASID (I/O Address Space ID) 是 Linux 内核内管理 PASID / Sub Stream ID 的组件。
系统中有很多 PASID user:
- CPU/MM 中使用 PASID MSR
- VFIO 分配 PASID
- IOMMU scalable mode 下维护 PASID 颗粒度的页表
- KVM 维护 guest PASID -> host PASID 页表
- Driver 本身 program PASID
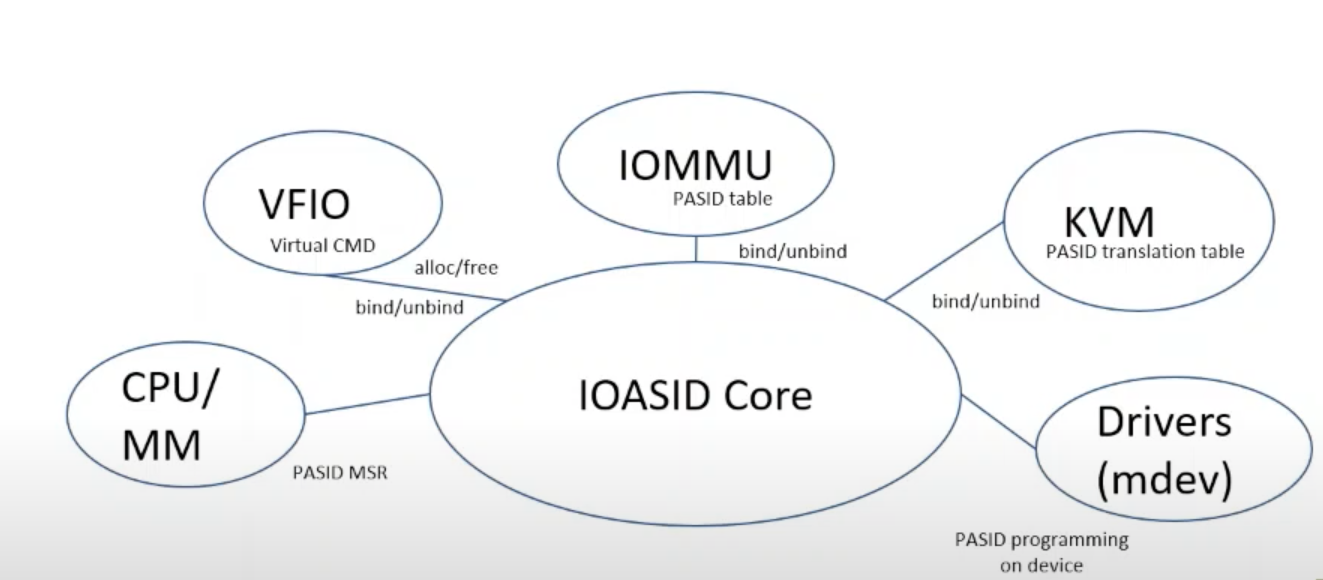
PASID Virtualization in KVM
PASID 本身由 Linux 内核分配管理。那么在虚拟化场景下,guest kernel 的 PASID 域与 host kernel 的 PASID 域是不同的。所以需要引入 PASID virtualization,即 guest PASID -> host PASID 的映射。这是 Intel VMX (KVM) 引入的新特性。
如图所示,guest PASID 00000H ~ 7FFFFH 和 80000H ~ FFFFFH 两个范围由两个 Directory 维护。
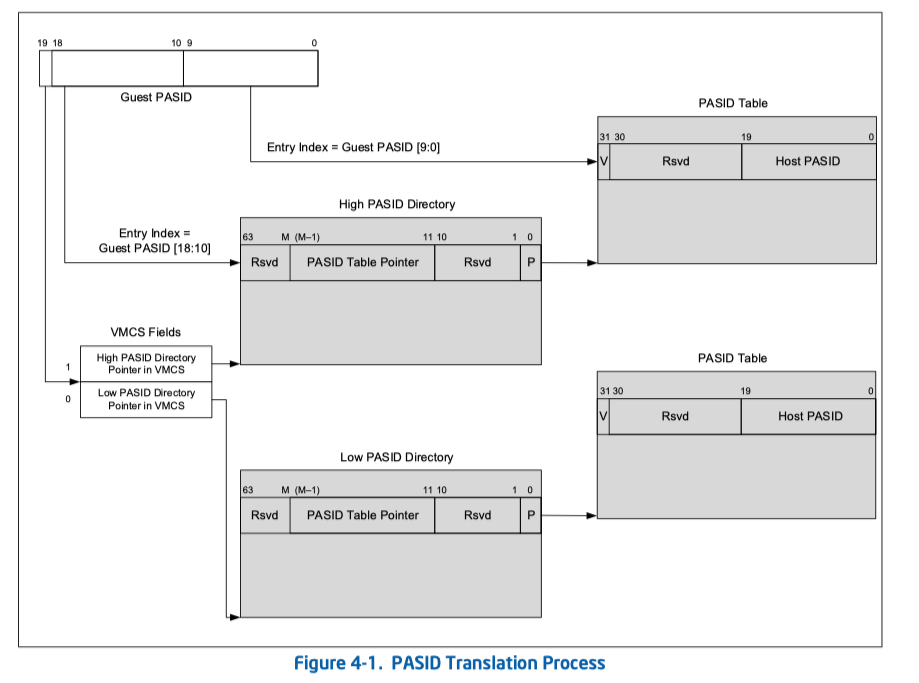
在 guest PASID 翻译失败的情况下,将会触发 VM exit。
DMWr
什么是 DMWr ?
Deferrable Memory Write (DMWr),一种 PCIe optional 的新增 non-posted 请求。
除了 PCIe 中常见的 Non-Posted 返回值 Successful Completion (SC)、Unsupported Request (UR)、Completer Abort (CA) 外,新增了 Request Retry Status (RRS) 返回值。如果 Completer 暂时不能完成该请求,可以返回 RRS,告知 Requester 这次请求被暂缓了;在 Requester 收到 RSS 后, 可以(但不强制要求)再次发送请求,请求内容允许与之前相同或有修改。
Completer 可以自行实现发送 RSS 的 policy,比如基于 fairness 考量,以 PASID、Requester ID、TC 等等作为参数。Completer 不能假设回复 RSS 后 Requester 一定会再次发送请求。
Requester 可以自行实现在何时、以及是否再次发送请求。
DMWr 的一个用例就是设备暴露单一的 Shared Work Queue 给多个 VM,然后以 PASID 为依据区分来自不同 VM 的请求,避免为每个 VM 分配单独的 Dedicated Work Queue 硬件资源。
值得注意的是,DMWr 是 non-posted 请求,意味着在 PCIe ordering 上,posted 请求可以 pass DMWr, 所以 posted write 的性能会比 DMWr 更好;另外所有 DMWr 请求没有 orderding。
ENQCMD/S
什么是 ENQCMD/S ?
ENQCMD/S 是在 SPR 平台上第一次引入的 CPU 指令。
这个指令其实就是 PCIe DMWr 的一种应用。
特定设备(如 SPR 内集成的 DSA)具备 enqueue registers 寄存器。ENQCMD/S 指令通过向 enqueue register 的 MMIO 写入 64 bytes command data 给设备下发 work descriptor。
command data 的低 20 位为 PASID;第 31 位为 0 时为 ENQCMD,即运行在 user space,第 31 位为 1 时为 ENQCMDS (enqueue command as supervisor),即运行在 kernel space (CPL0)。
ENQCMD (enqueue command) 的 PASID 值来源于 IA32_PASID MSR。kernel 负责 process 的 PASID 分配,并在 context switch 时,通过 XSAVE feature set 更新 IA32_PASID MSR,并在 ENQCMD 指令执行时自动填入 PASID 字段。这个过程对 user space application 是透明的,这也避免了 application 恶意占用 PASID。
ENQCMD/S 支持虚拟化。对应的 IA32_PASID MSR 也支持虚拟化。
而 ENQCMDS 顾名思义运行在 kernel space, 所以 ENQCMDS 的 PASID 由 kernel 直接管理。
而设备 DMA 时也会带上相同的 PASID tag,携带进程信息。

ENQCMD/S 就使用了上一节介绍的 PCIe DMWr 请求。RFLAGS register 的 ZF flag bit 作为它的返回值,0 为 sucess,1 为 retry,与 DMWr 的 RRS 返回值含义相同。
ENQCMD/S 可以解决硬件 dedicated work queue (DWQ) 资源不足的问题,多个 client 可以共用同一个 shared work queue (SWQ)。
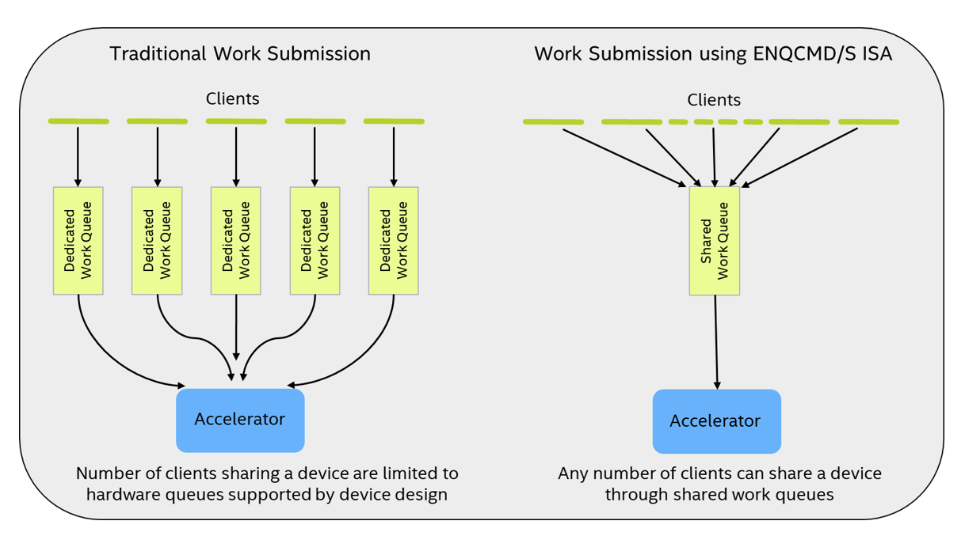
这里举一个虚拟化场景下,发送 ENQCMD 的例子:
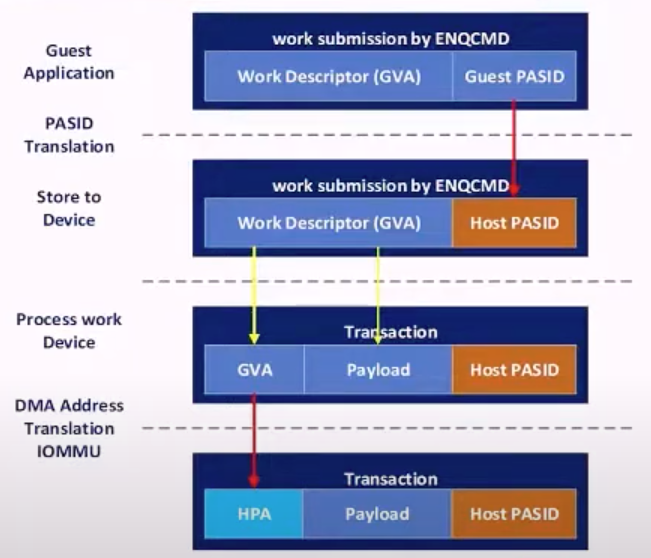
- guest user space 发起 ENQCMD,PASID 为 guest PASID,来源是透传的 IA32_PASID MSR,Work Descriptor 是 guest 填充的 GVA
- KVM 侧负责 gPASID -> hPASID 的翻译
- ENQCMD 填入设备
- 设备发起 DMA 时,IOMMU 结合 BDF 以及 hPASID,将 GVA 翻译至 HPA
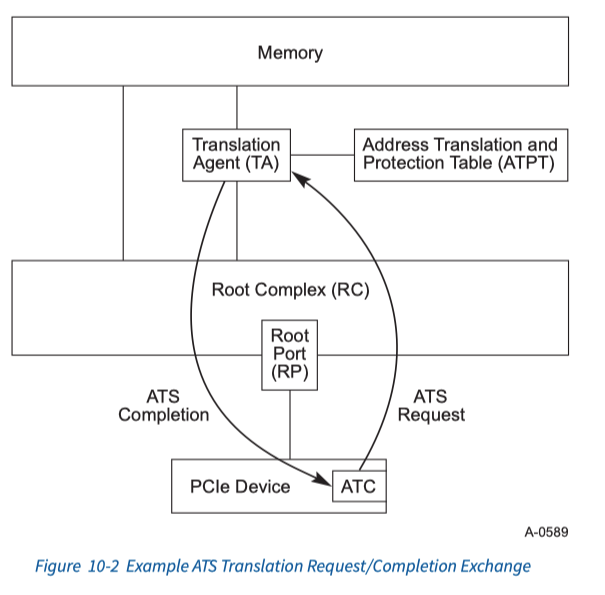
ATS
什么是 ATS?
ATS 引入的原因是为了缓解集中在 IOMMU 的查表压力,将部分 translation table 分布至设备 cache,这样 EP 出来的地址就是物理地址,不需要再 walk 一遍内存中的页表,节省地址翻译的时间。
ATS (Address Translation Service) 引入的 ATC (Address Translation Cache) 和 CPU 的 TLB 类似,是页表地址翻译的 cache。
PCIe TLP 中新定义了 AT bits。00b 表示 ATS 没有开启。01 表示地址翻译请求,10b 表示地址已经翻译。

PRI / PRS
什么是 PRI / PRS ?
透传 VFIO 设备的虚机必须 pin 住所有 guest 内存才能保证设备 DMA 时 page 不会已经被 swap 出去,但从 host 角度来看,这意味着内存资源的浪费。
而 Page Request Service (PRS) / Page Request Interface (PRI) 就可以解决这个问题。
PRI (Page Request Interface) / PRS (Page Request Service) 是 ATS 的扩展功能,依赖于 ATS。开启 ATS 可以不开启 PRS,但开始 PRS 时一定开启 ATS。
开启 ATS 和 PRS 后,一次设备 DMA 的流程如下:
- 设备发起 DMA 访问内存,首先查找本地 ATC
- 如果 ATC entry 命中,拿到翻译后的物理地址,继续 DMA -> 结束
- 如果 ATC entry 没有命中,ATS 向 IOMMU 的完整页表查询
- 如果 IOMMU 内页表存在,ATS 将其 cache 进 ATC,继续 DMA -> 结束
- 如果 IOMMU 内页表不存在(page fault),设备发起一次 PRI,让缺失的页 page in 内存,并更新 CPU 的 TLB 和设备的 ATC
- 缺页处理完成后,ATS 通知设备,PRI 完成
- 设备再次向 ATS 发起地址翻译请求,ATC entry 命中,继续 DMA -> 结束
Page Request Message 的 Page Address [11:0] bits 忽略,因为 page 至少以 4K 为单位。
同组的多个 Page Request 可以共用一个 Group Index,RC 需要收到同组所有的 Page Request 后才能开始处理。但没有提前被告知 Page Request 数量,RC 怎么知道什么时候是最后一个 Page Request 呢?Page Request Message 中有 Last flag,置 1 时表示这是同组中的最后一个 message。但问题又来了:Page Request 如果是 Relax Ordering 的,Last flag 为 1 的 message 会不会跑在别人前面,导致 RC 错误地提早处理了?所以规定:Last flag 为 0 的message 可以 Relax Orderding,但 Last Flag 为 1 的 message 不允许 Relax Ordering,必须最后一个到达 RC。

SVA / SVM
什么是 SVA ?
SVA (Shared Virtual Addressing) 指设备和处理器使用相同的虚拟地址空间的能力。
SVA 也被称为 SVM (Shared Virtual Memory),但社区倾向用 SVA,避免与 Secure Virtual Machine 混淆。
SVM 带来的好处有两个:
- device 和 cpu 共用相同的内存指针,降低软件复杂度
- 设备 DMA 时具备了和 cpu 类似的缺页处理,不再需要 pin DMA page
SVA 能力需要三个方面特性的支持:
- 每个设备内支持多份地址空间,比如 PASID
- IO page fault 的支持,比如 PCIe 的 PRI
- MMU 与 IOMMU 页表的兼容
SVA 在各个平台上的实现不一样,比如 Intel 和 ARM 上各自有一套术语,但大体上含义一样。
Summary
以上的名词概念很多,逐个理解之后,我们就可以梳理一下它们之间的关系。
SVA 的目的是让 device 和 cpu 共用一个虚拟地址空间,能降低编程复杂度,并解决虚拟化设备透传时的 pin 页要求。
那么实现 SVA 这个目的,遇到的第一个问题就是,device 的 DMA 请求(IOMMU)默认是以 BDF 为单位的,但 cpu 的内存访问(MMU)是以 process 为单位的,两者的颗粒度不一样(一个 BDF 可以被多个进程使用,无法区别)。所以需要开启设备的 PASID feature,让设备 DMA 也以 process 为单位。
那么现在 DMA 以 PASID 为单位了,本来 IOMMU 以 BDF 为单位建立页表的方式也需要修改,变成以 PASID 为单位建立页表,也就是 IOMMU scalable mode。
现在设备和 cpu 用一套虚拟地址了,第二个问题就来了:device 现在看到的地址和 cpu 一样,cpu 缺页时有 page fault,device DMA 缺页时怎么办?所以需要使能 ATS 和 PRI,这一套机制可以处理 DMA 缺页,带来的另一个好处就是 DMA 不需要 pin 内存了。当然 PRI 有了额外的 overhead,性能上肯定不如 pin 内存好。
以上就是 SVA 相关的技术点。
然而启用 PASID 后,带来了其他好处,比如引入了 Shared Work Queue。没有 PASID 之前,硬件需要预留 dedicated work queue 的 MMIO 资源,给每个 process 单独分配,这样硬件资源的开销很大,scalability 也很低,不可能给几千个进程都分配物理资源。为此 Intel 引入了 ENQCMD/S,这个指令携带 PASID 信息,多个进程可以向同一个 work queue 写入。当然 SWQ 在性能上不是最优的,因为其本质是 DMWr,需要返回值,是 non-posted 的。
启用 PASID 后的另一个好处就是 SIOV。SIOV 的基础就是以 PASID 为隔离单位进行虚拟化。
SIOV 与 SVA 本身是正交的,但因为都以 PASID 为基础,有很多共同的技术点。
发表回复